How to Use the “Infinite Scrolling” Method in Javascript to Manage Large API Result Sets

For today’s fun adventure we will be building our own “infinite scrolling” results page for data from the tmdb API.
Surely you’ve experienced old-school pagination (see image above) at some time or other. It’s a clunky and unwieldy way to view large data sets over the web, and for extra-large sets it can make drilling down into your data feel more like river-panning for data nuggets.
What we’re going to build today is the foundation protocol to achieve this type of result instead. Here’s a working model of what we will be setting up today.

What you’re going to need:
— an API key from tmdb. Just go down there, sign up for an account, get an API key (it’s free!) and come right back. I’ll wait.
Okay, great! Now let’s get creatin’!
What we’re going to do is access the current year’s movies from the API. Then we’ll print each movie’s poster to the screen. When the user scrolls to the bottom of the page, we’ll use that to trigger another API call to retrieve more results and simply append them to the output.
If you’ve ever found yourself wondering why so many APIs nowadays are returning results with a hard-maximum limit of 20 records or so, that’s because this method is so easy to implement it’s actually easier to just do it this way than it is to fumble around with pagination.
First we’re going to make an html web page to output our results. I’m keeping everything bare-bones here so you can just focus on the relevant goods:
<!DOCTYPE html>
<html>
<head><style>
#output {
width:50%;
margin-left:auto;
margin-right: auto;
margin-top: 20px;
}
</style>
</head><body>
<div id=”output”></div><script src=”main.js”></script></body>
</html>
Yep, that’s the whole page. Just a big ‘ol empty div in the middle of the page. That’s what the “width:50%;margin-left:auto;margin-right:auto;” in the style tells it to do.
Now we just need to code the functionality to fill that div up with movie posters and keep it filling up as you scroll down through the contents.
Obviously, from the “script” tag in the code, we’re going to be calling our Javascript file “main.js” so let’s start that one now.
First we need to setup our global variables:
// you’re going to need your own API key that
// you can get from https://www.themoviedb.org
let APIkey = your API key here;// we always start at the first page of data results
let pageNum = 1;// So we can store our movie details when they’re loaded
// and not have to call the API every time
let movies = [];// for our example we’ll just use movies from 2020
// but you can make this a variable that the user
// can change
let year = 2020;
Next, we’ll set up the function call to retrieve one set of results from the API. They’re only sent with 20 records at a time, so we’ll be calling this function a lot:
const getMoviesByYear = (year,page) => {// when the user changes genres or year, we need to clear
// the movies array out instead of just filtering
// so it doesn’t add the same movie twiceif (page===1) {movies=[];}// url to the API
let url = `https://api.themoviedb.org/3/discover/movie?api_key=${APIkey}&language=en-US&sort_by=popularity.desc&include_adult=false&include_video=false&primary_release_year=${year}&page=${page}`;// we’re going to build some HTML for the output
let htmlStr = “”;// the root path to the image files
let imgPath = `https://image.tmdb.org/t/p/w154/`;fetch(url)
.then(results => results.json())
.then(data => {
for (let i = 0;i<data.results.length;i++){
if (data.results[i].poster_path) {
movies.push(data.results[i]);
htmlStr+=`<div style=”float:left;”><img src=”${imgPath}${data.results[i].poster_path}” style=”height:230px;width:154px;border-radius:5%;”></div>`;
}
}document.getElementById(“output”).innerHTML+= htmlStr;
})
}
So. What’s going on in this function?
I started off with this line
if (page===1) {movies=[];}to give you an idea of some of the things you can do with all this delicious data. In the case of Flix, I store all the result data from the API into an array of movies. That way I still have access to all the extemporaneous data that I don’t happen to be displaying at the moment.
Just because we’re only displaying the poster picture doesn’t mean there isn’t an insane amount of other good data that’s included in the results. You’ll notice a little further into that function is where I add each new movie object to the array:
movies.push(data.results[i]);Next we give it the URL to the API endpoint that gives us results. Remember that tmdb API only provides result sets of 20 elements, but it also keeps track of the current page of those elements for you. So our API URL looks like this:
let url = `https://api.themoviedb.org/3/discover/movie?api_key=${APIkey}&language=en-US&sort_by=popularity.desc&include_adult=false&include_video=false&primary_release_year=${year}&page=${page}`;As you can see, we’re also sorting it by the coolest movies first, filtering out the pr0n and movies with videos. All this stuff and other cool parameters you can find from the API documentation. It provides some pretty comprehensive data.
Notice the part that says:
primary_release_year=${year}&page=${page}The ${year} and ${page} are template literals that include the year and page parameters from the function call into the url.
The next lines are pretty much rote:
fetch(url)
.then(results => results.json())
.then(data => {We fetch the API at the URL, then we name the results results and convert them into a JSON array which we call data.
Here’s the meat of the function:
for (let i = 0;i<data.results.length;i++){
if (data.results[i].poster_path) {
movies.push(data.results[i]);
htmlStr+=`<div style=”float:left;”><img src=”${imgPath}${data.results[i].poster_path}” style=”height:230px;width:154px;border-radius:5%;”></div>`;
}
}We loop through our data array. The “if” statement is to filter only by elements that actually have a poster image, so we don’t get a bunch of blank spaces with an “X” in them where missing posters are.
You might want to provide some sort of alternate image for cases like that so you can still provide the user with the movie data even though there’s no poster, but for this example we’re trimming it out completely if there’s no poster.
Then we add that particular data element into our own array:
movies.push(data.results[i]);Now we have a copy of the API results in the browser’s memory that we can use later.
Finally, we build the HTML code that we’re going to add to our page to show each poster:
htmlStr+=`<div style=”float:left;”><img src=”${imgPath}${data.results[i].poster_path}” style=”height:230px;width:154px;border-radius:5%;”></div>`;We’re putting each poster inside a DIV element, smashing them all to the left until they start wrapping down the screen — because the DIV they’re in is only 50% wide — and we’re giving them a sexy rounded corner so they look cool:
border-radius:5%;That loop creates all the HTML to produce a div with 20 posters in it, but we still haven’t drawn it to the screen. We do that with this last line:
document.getElementById(“output”).innerHTML+= htmlStr;And there you’ve fetched an API, gotten the results and displayed them to the screen. You can see that we’re using the “+=” operator to append new results to our output DIV instead of just replacing the contents by using “=”.
Now lets get crazy with it and load more results when the user scrolls through all the current ones!
We need to set up our infinite scrolling function. Let’s call it something descriptive, like infiniteScroll, and make it look a little like this:
// this event-handler checks if the scrollbar is at the
// bottom of the page and if it is it fetches another
// set of recordslet isScrolled=false;const infiniteScroll = () => {// End of the document reached?
if (window.scrollY > (document.body.offsetHeight — 100) && !isScrolled) {// Set “isScrolled” to “true” to prevent further execution
isScrolled = true;// Your code goes here
pageNum++;
getMoviesByYear(year, pageNum);// After 1 second the “isScrolled” will be set to “false” to allow the code inside the “if” statement to be executed againsetTimeout(() => {
isScrolled = false;
}, 1000);}
}
Here’s the hard part:
if (window.scrollY > (document.body.offsetHeight — 100) && !isScrolled) {window.scrollY is a read-only property that returns the exact location (with decimal precision) of where the scrollbar currently is.
document.body.offsetHeight is the actual height of the body including padding and borders, but not margins.
There are about 20 dozen different configurations of DOM properties that you can compare to make this decision.
* the big challenge for a project like this comes when your infinite scroller is being performed on a deeply nested DIV and has to accommodate for all the surrounding display elements’ CSS **
So if that condition is met, then we set our isScrolled variable to “true.” We do that so it won’t just instantly keep performing more and more fetch calls. We’re ultimately going to make it wait a second between calls.
That’s right. We have to slow it down because it will try to load more data too fast. That’s how you start running into a 429 error result: “Using our API too much!”
Since we want to load more data, we’re going to need to get the API URL for the next set of 20 results, so we increment our pageNum global variable and call our fetch routine again.
pageNum++;
getMoviesByYear(year,pageNum);Remember, year and pageNum are both global variables, so they maintain their values even outside the functions where we use them.
At this point if you load your page into a browser nothing’s going to happen. That’s why we need to set up our initial calls and our event-handlers. This is also the last piece of the puzzle!
// bind the infinite scroll to all needed events
window.onscroll= function() {infiniteScroll();}// everything starts here!
window.onload = () => {
getMoviesByYear(year,pageNum)
}
And that’s it! We set an event-handler to call our infinite scroller function every time the user scrolls the window:
window.onscroll= function() {infiniteScroll();}And now that that’s taken care of, our page is all loaded and ready to go, so we initialize everything by making our call to get the first set of data:
window.onload = () => {
getMoviesByYear(year,pageNum);
}Now if you pull up your page in the browser, you should be happily staring at this:
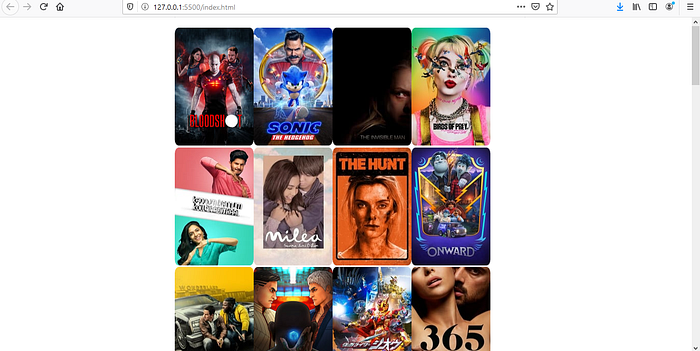
Remember how you only get 20 results from each API call for tmdb? There are already 12 showing in the image, but you can tell by the scrollbar that I’ve already scrolled some and plenty more data has been fetched and added.
so exciting
Infinite-scrolling is a fun and fantastic — and simple(!) — way to provide your user with a seamless interface for the data they want. You may recognize some sites that already use this method, like Facebook, Reddit, Twitter and so on.
Caveat: I don’t remember exactly where, but I seem to remember hearing that some people wanted to legislate the use of this technique because of its potential to manifest or exploit addictive behavior in the end user!
nm…here’s one now.

